


Today is a big day. Together, we will explore the different database isolation levels. Put on your seatbelt, it’s going to be a wild ride into the realm of database isolation levels and anomalies!

In a previous issue (Isolation Level), we introduced the concept of isolation level. In short, an isolation level refers to the degree to which concurrent transactions1 are isolated from each other. Understanding the different levels is important for any software engineer working with databases. As I mentioned previously, I have already faced significant problems with customer data because we didn’t properly tune our PostgreSQL config.
In this issue, we will explore the different isolation levels and the anomalies each one prevents. In this context, an anomaly refers to an undesirable behavior that can occur when multiple transactions execute concurrently. Said differently, if something unexpected happened because we have two transactions running at the same time, we faced an anomaly.
Here are the different isolation levels and all the anomalies they prevent:

For example:
The read uncommitted level prevents dirty writes
The read committed level prevents dirty reads and dirty writes as it’s built on top of read uncommitted
The higher the isolation level and the more anomalies are prevented. Yet, as with anything in computer science, it’s not free and it comes at a cost of reduced performance. For example, in a benchmark I observed a drop of around 80% in throughput by tuning the isolation level2.
No Isolation
Anomalies prevented: none.
The no isolation level implies that we don’t impose any isolation at all. This is only suitable in scenarios where we can ensure no concurrent transactions will occur. In practice, this is quite rare.
Read Uncommitted
Anomalies prevented: dirty writes.
Dirty Writes
A dirty write occurs when a transaction overwrites a value that was previously written by another transaction that is still in flight3. If either of these transactions rollback, it’s unclear what the correct value should be.
To illustrate this anomaly, let’s consider a banking account database with two transactions doing concurrent operations on the same account of Alice:
Initial state:
Alice’s balance: $0
Transactions:
T1adds $100 to Alice’s account but will rollbackT2adds $200 to Alice’s account
Expected balance: $200
Here’s a possible scenario with a database that doesn’t prevent dirty writes (the operation that causes problems is highlighted in red):
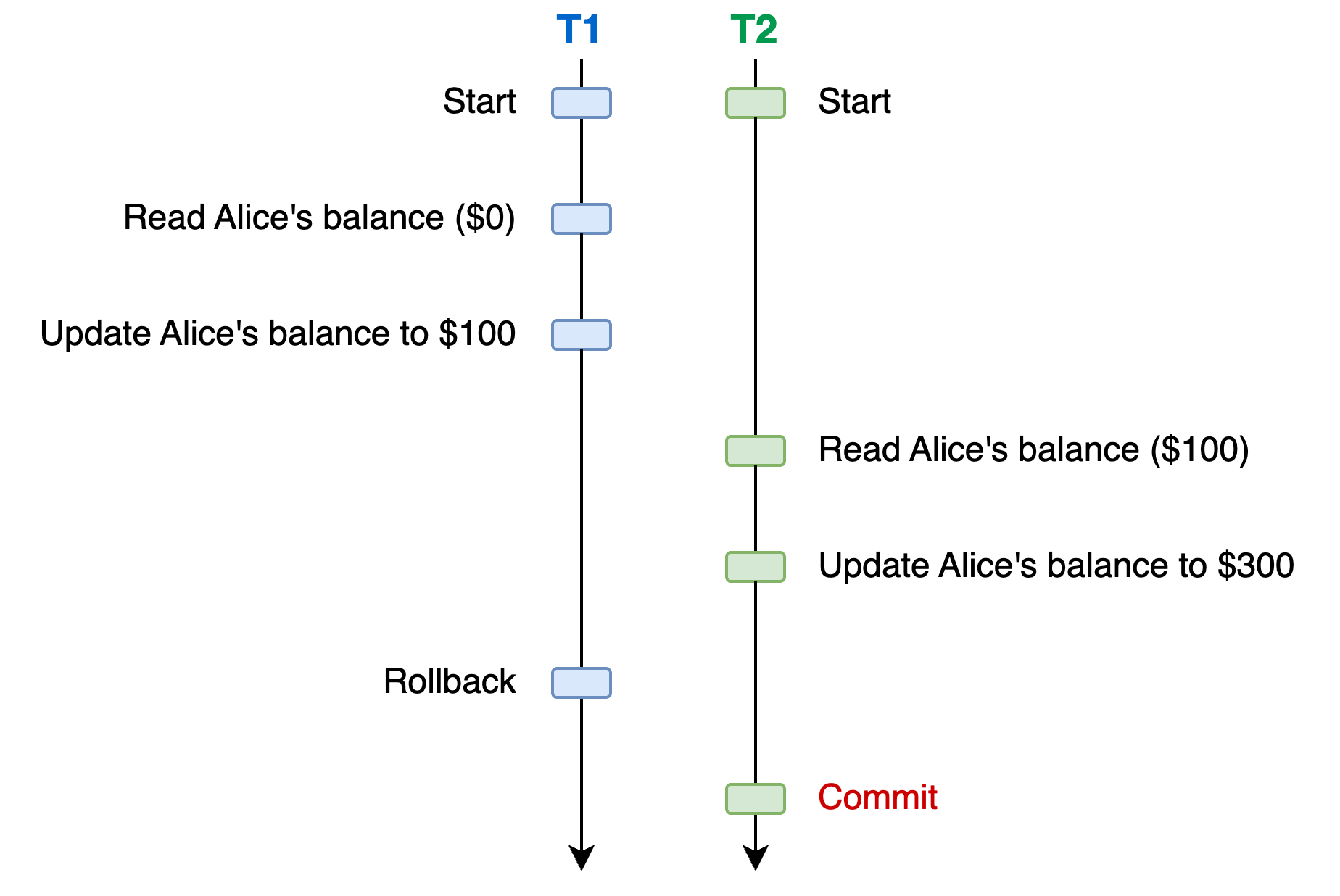
At the end of this scenario, Alice’s balance is $300 instead of $200. This is a dirty write. Dirty writes are especially bad as they can violate database consistency4. In general, databases prevent dirty writes by locking rows that will be written until the end of the transaction.
If our database is tuned with the read uncommitted isolation level or higher, we won’t face dirty write anomalies. Otherwise, dirty writes may occur.
Read Committed
Anomalies prevented: dirty reads.
Dirty Reads
A dirty read occurs when one transaction observes a write from another transaction that has not been committed yet. If the initial transaction rollbacks, the second transaction has read data that was never committed.
Let’s consider the same banking account example:
Initial state:
Alice’s balance: $0
Transactions
T1adds $100 to Alice’s account but will rollbackT2reads Alice’s balance
Expected
T2read: $0
Here’s a possible scenario with a database that doesn’t prevent dirty reads:

The balance read by T2 is $100, which corresponds to a dirty reads. Indeed, $100 on Alice’s account is something that never really existed as it was rollbacked by T1. With dirty reads, decisions inside transactions can be taken based on data updates that can be rolled back, which can lead to consistency violations, just like dirty writes.
At the read-committed isolation level, databases address this problem by ensuring that any data read during a transaction is committed at the time of reading.
Repeatable Reads
Anomalies prevented: fuzzy reads.
Fuzzy Reads
A fuzzy read occurs when a transaction reads a value twice but sees a different value in each read because a committed transaction updated the value between the two reads.
Let’s again consider the same banking account example:
Initial state:
Alice’s balance: $0
Transactions:
T1reads Alice’s balance one time and then a second timeT2adds $100 to Alice’s balance
Expected
T1reads should be consistent: either $0 and $0 or $100 and $100, depending on the execution order
Here’s a possible scenario with a database that doesn’t prevent fuzzy reads:

Here the problem is that T1 reads Alice’s balance two times and got two different results: $0 and $100. This is the reason why fuzzy reads are also called non-repeatable reads. We can easily see the impact of fuzzy reads, if a transaction doesn’t expect two reads for the same value not to be the same, it can lead to logical errors or even rule violations.
At the repeatable reads isolation level, databases, in general, prevent fuzzy reads by ensuring that a transaction locks the data it reads, preventing other transactions from modifying it.
Snapshot Isolation (SI)
Anomalies prevented: fuzzy reads, lost updates, and read skew.
We already introduced fuzzy reads in the context of the repeatable reads isolation level. Therefore, if we want to prevent fuzzy reads, we have to choose at least the repeatable read or SI isolation level.
One thing to note, though, is that preventing fuzzy reads at both isolation levels is done differently. We said that at repeatable reads level, transactions lock the data it reads. Yet, snapshot isolation works with consistent snapshot of the database at the start of the transaction, isolating it from changes made by other transactions during its execution. This technique also helps to prevent lost updates and read skew, which we will introduce now.
Lost Updates
A lost update occurs when two transactions read the same value, try to update it to two different values but only one update survives.
Same banking account example:
Initial state:
Alice’s balance: $0
Transactions:
T1adds $100 to Alice’s accountT2adds $200 to Alice’s account
Expected balance: $300
Here’s a possible scenario with a database that doesn’t prevent lost updates:

The final balance is $200, which reflects T2’s write, but T1’s update of +$100 is lost. This illustrates why this anomaly is called a lost update and it’s problematic as it can lead to incorrect data, violating the expectation that both additions should be applied to Alice’s account.
At the SI level, as transactions work with a consistent snapshot of data, the database can detect a conflict if two transactions modify the same data and typically rollback the transaction.
Read Skew
A read skew occurs when a transaction reads multiple rows and sees a consistent state for each individual row but an inconsistent state overall because the rows were read at different points in time with respect to changes made by other transactions.
If you understood the definition right away, congratulations. Otherwise, let’s make it clearer with a banking database example and consider two accounts, Alice and Bob:
Initial state:
Alice’s balance: $100
Bob’s balance: $0
Transactions:
T1reads Alice’s and Bob’s balanceT2transfers $100 from Alice’s account to Bob’s account
Expected
T1reads should be consistent: $100 for Alice and $0 for Bob or $0 for Alice and $100 for Bob depending on the execution order
Here’s a scenario that illustrates a read skew anomaly (the transfer operation is simplified for readability reasons):

Before and after these transactions, the sum of Alice’s and Bob’s balances is $100; yet, this isn’t what was observed by T1 in this scenario. Indeed for T1, Alice’s and Bob’s balance are both $100 which represents a sum of $200. This illustrates a read skew: a consistent state for each individual balance, but an inconsistent state overall with the total balance. Read skew can also lead to consistency rules to be violated.
At the SI level, snapshots also allow to prevent read skews as in this example, T1 would work on a consistent snapshot, leading to consistent data.
Serializable Snapshot Isolation (SSI)
Anomalies prevented: write skew.
Write Skew
A write skew may occur when two transactions read the same data, make decisions based on that data, and then update that data.
For this anomaly, let’s consider an oncall scheduling system for doctors at a hospital. The hospital enforces a consistency rule that at least one doctor must be oncall at any given time:
Initial state:
Alice and Bob are both oncall
They both feel unwell
Transactions:
Both decide to ask the system if they can leave:
T1represents Alice’s request andT2represents Bob’s request
Expected result: Only Alice’s or Bob’s request is accepted
Now, let’s consider the following scenario that illustrates a write skew:
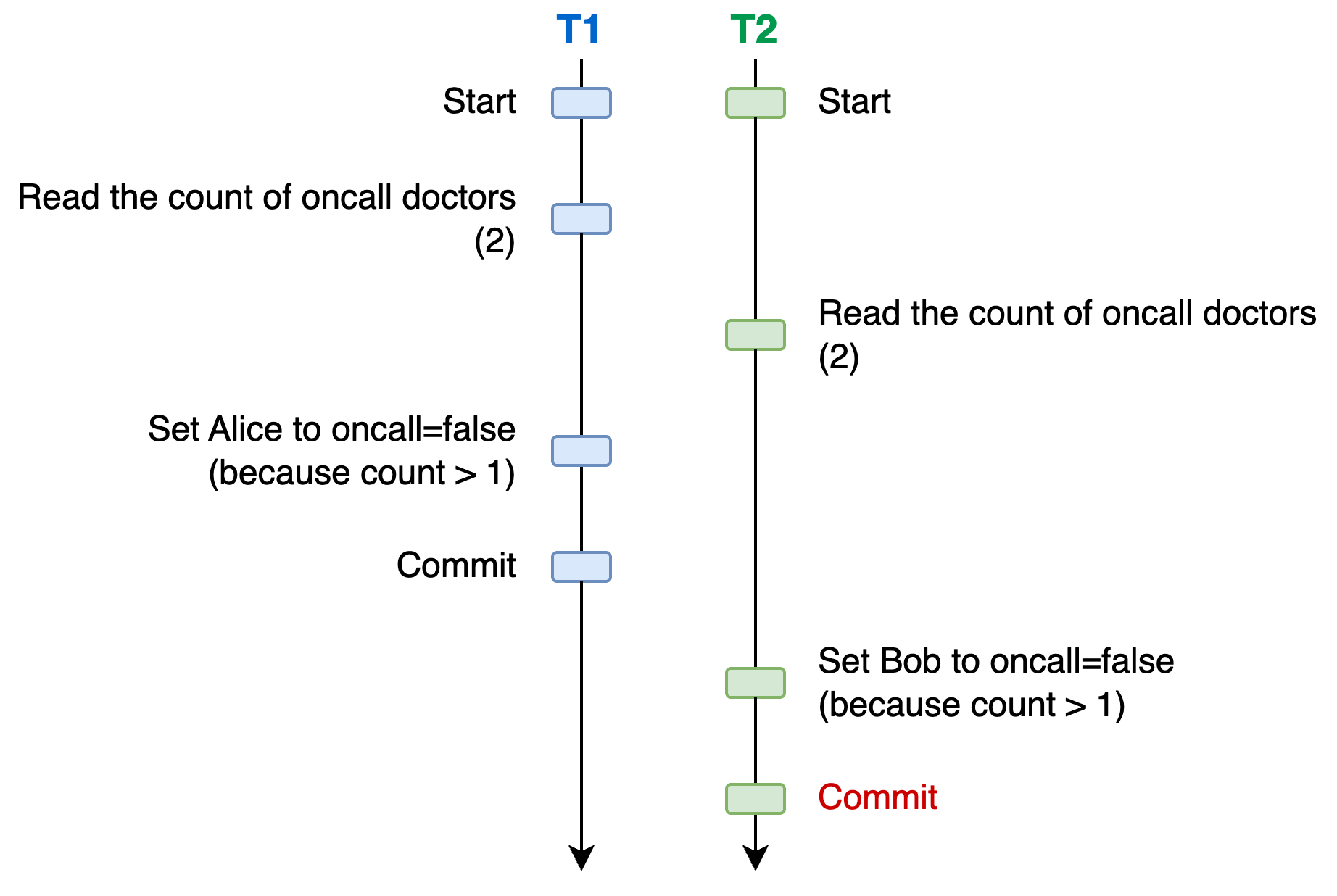
In this scenario, both transactions take the decision to accept the sick leave because they read a count of oncall doctors greater than 1. It results in a violation of the consistency rule to keep always at least one oncall doctor.
SSI is an advanced approach that extends SI. Usually, databases tuned at SSI prevent write skew by introducing additional checks during the commit phase, which ensures that the changes made by different transactions do not lead to inconsistent or conflicting states.
Serializability
Anomalies prevented: phantom reads.
Phantom Reads
A phantom read occurs when a transaction does multiple predicate-based read, while another transaction creates or deletes data that matched the predicate of the first transaction. A phantom read is a special case of fuzzy read (non-repeatable read).
Let’s consider the example of a database tracking the students of computer science courses. The predicate in this scenario will be WHERE course = ‘Algo101‘:
Initial state:
Course Algo101 has a certain number of students
Transactions:
T1selects the max age and then the average age of students in the Algo101 courseT2updates the list of students to the Algo101 course
Expected
T1reads to be consistent
Here’s a scenario that illustrates phantom reads:

In this scenario, T2 affected T1’s result set. T1 first query returned a given result set that was different from the second query. This could lead to consistency rules violation as well. For example, if T2 inserts many “old“ students, T1 might as well compute an average age that could be higher than the max age. This is a phantom read: when the set of rows satisfying a predicate changes between reads within the same transaction due to another transaction.
The serializability isolation level ensures the same result as if transactions were executed in a sequential order, meaning not concurrently. Therefore, serializability prevents phantom reads by guaranteeing that no new rows are inserted, updated, or deleted in a way that would change the result set of the transaction’s query during its execution.
Serializability is the highest possible isolation level, and it refers to the I of ACID.
NOTE: There’s also the concept of strict serializability, which is even stronger than serializability. Strict serializability is not strictly an isolation level but rather exists at the intersection of isolation levels and consistency models. It combines the properties of serializability and linearizability to ensure both a serial order of transactions and a respect for real-time ordering. We will address this concept in a future issue.
Conclusion
Let’s summarize all the anomalies:
Dirty writes: When a transaction overwrites values that was previously written by another in-flight transaction.
Dirty reads: When a transaction observes a write from another in-flight transaction.
Fuzzy reads: When a transaction reads a value twice but sees a different value.
Lost updates: When two transactions read the same value, try to update it to different values, but only one update survives.
Read skews: When a transaction reads multiple rows and sees a consistent state for each individual row but an inconsistent state overall.
Write skews: When two transactions read the same data, and then update some of this data.
Phantom reads: When the set of rows satisfying a predicate changes between reads within the same transaction due to another transaction
As I mentioned, understanding the different isolation levels should be an important skill for any software engineer working with databases. While serializability offers the highest isolation guarantees, it can have a significant impact on performance, especially in high-concurrency systems. Therefore, it’s crucial to understand the anomalies that can occur at each isolation level and evaluate which ones are acceptable for our system. Sometimes, a system might tolerate certain anomalies in exchange for improved throughput.
By making informed decisions about the appropriate isolation level, we can balance the trade-offs between data consistency and system performance based on the needs of our systems.

Explore Further
I've wanted to write about database isolation levels for years, and it’s been a lot of fun for me. If you enjoyed this post, I would love to hear from you! I think a similar deep dive into consistency models could be just as important, so let me know if you'd be interested in that as well.
We already discussed the concept of transactions in Transactions.
The number itself doesn’t matter. It depends on many factors such as the database, the isolation levels tested, etc. Yet, it’s here to give a sense of what can be observed.
In-flight transaction = a transaction that has not yet been committed or rollbacked.
Great content, thank you so much!