



Instruction Pipelining
What It Is and Why It Matters for Developers

Hello! Today, we will discuss CPUs and the concept of instruction pipelining. This post lays the foundation for understanding CPU concepts we will introduce in future posts.

Rather than starting with a definition of instruction pipelining that many would find unclear, let’s first understand why it’s necessary by exploring how CPUs process instructions. This will give us a clearer picture of the problem and why it’s a fundamental technique in modern CPUs.
A CPU typically processes an instruction through four stages:
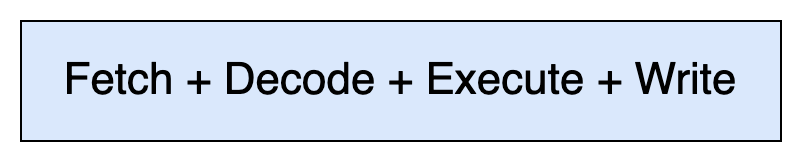
Fetch: Fetch the instruction from memory.
Decode: Decode the instruction to understand what operation is required.
Execute: Execute the operation (e.g., arithmetic or logic operations).
Write: Write the result back to memory or a register.
NOTE: This is a simplified view, but it should be enough to understand today’s concept.
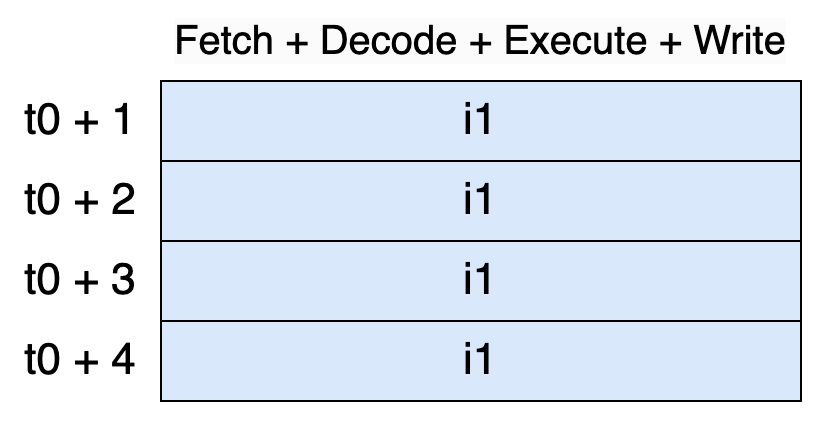
Assume that each of these stages takes one cycle to complete. Therefore, processing a single instruction would take four cycles (i1 stands for instruction 1):
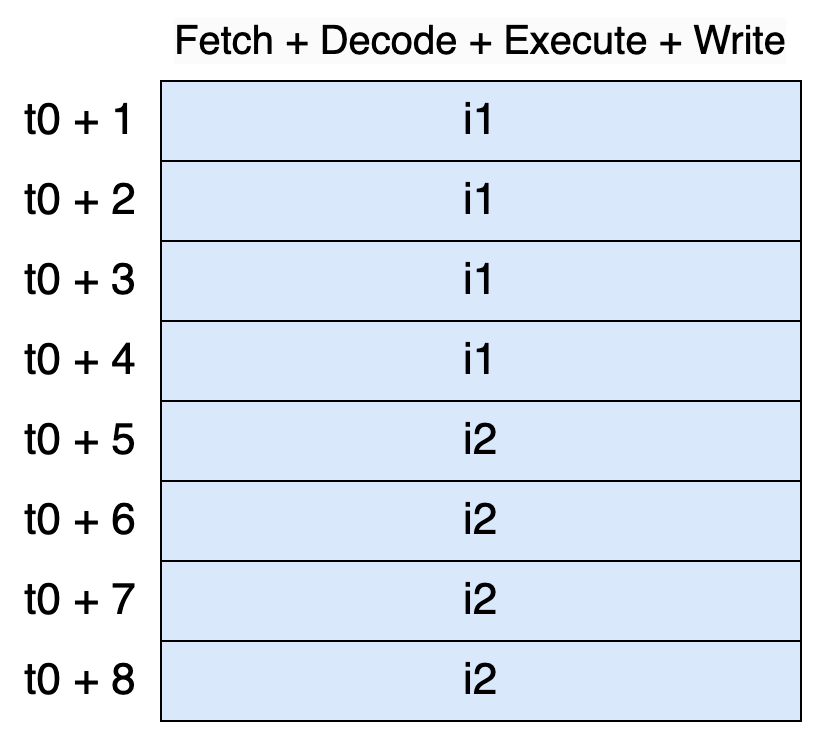
And processing two instructions would then take eight cycles:
If we were a CPU designer, how could we make things faster?
One way to speed things up would be to increase the CPU clock frequency. For example, if a CPU runs at 0.1 GHz, it takes 80 nanoseconds to complete eight cycles. If the frequency is doubled to 0.2 GHz, it takes 40 nanoseconds to complete those eight cycles. However, increasing clock frequency isn’t without its downsides. Higher frequencies lead to greater power consumption and increased heat, which can result in thermal throttling1. So clock frequency has limits and cannot be endlessly increased.
Another approach is to split the different stages into independent units (we will understand a bit later why it makes things faster):
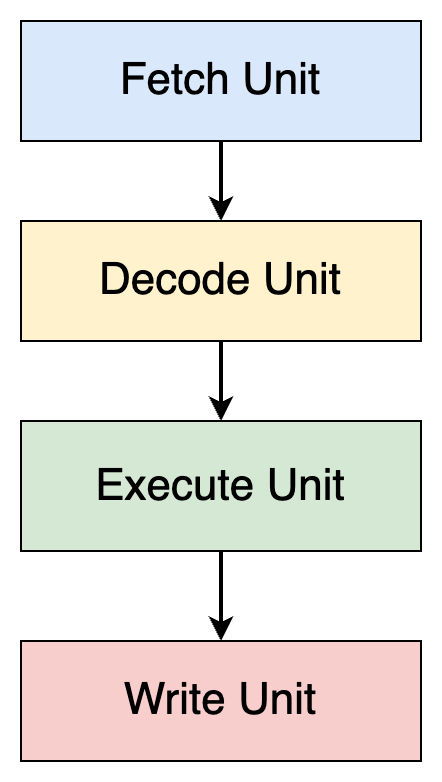
Fetch Unit (FU): Fetch an instruction.
Decode Unit (DU): Decode the instruction.
Execute Unit (EU): Execute the instruction.
Write Unit (WU): Write back the result.
NOTE: The internal design and organization of a CPU, including how it executes instructions, is called CPU microarchitecture. This four-stages design is only one example, some microarchitectures use different pipeline depth such as Intel’s NetBurst with 20+ stages.
Now, let’s visualize how our new CPU would handle two instructions:
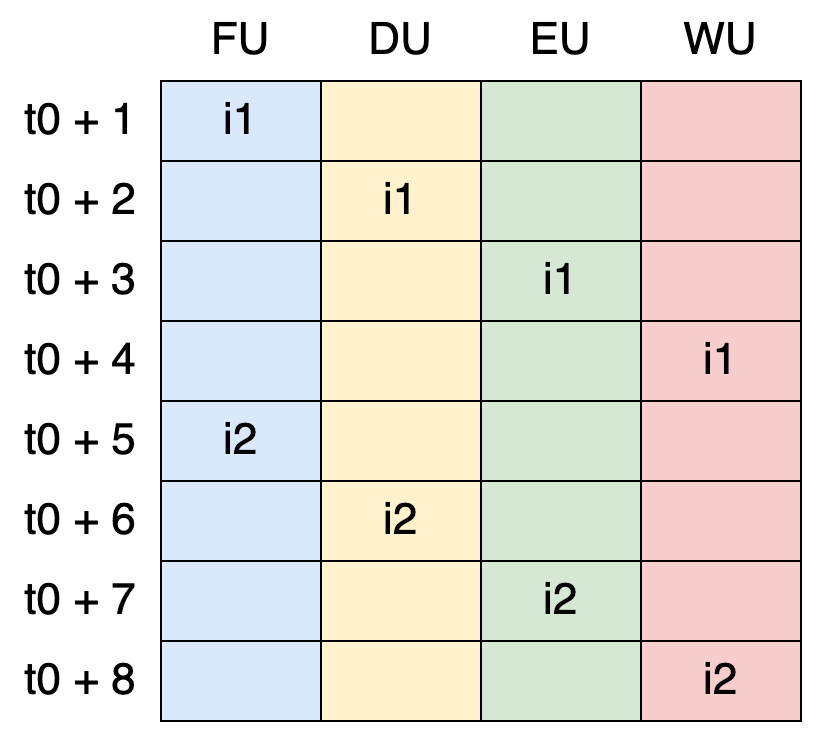
Nothing has changed in terms of cycles. It still takes eight cycles to process the two instructions (just like with the monolithic CPU). However, something important stands out: each unit is only active one out of every four cycles. In other words, during three cycles, the units are stalled.
To solve this inefficiency, it’s now time to introduce the concept of instruction pipelining. This technique is used in CPUs to improve performance by overlapping the execution of multiple instructions.
For example, once the FU completes fetching i1, it can immediately begin fetching i2:
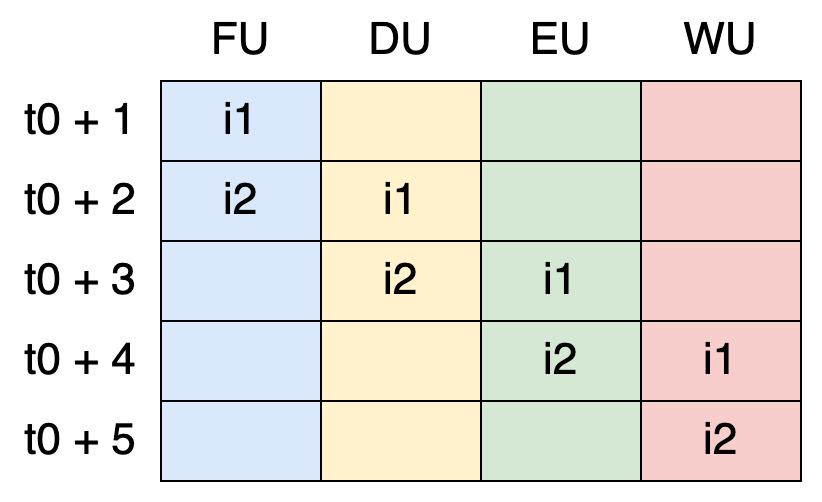
Now, the execution becomes faster. Although it still takes four cycles to complete the first instruction, only one additional cycle is needed to complete the second instruction.
Here’s a larger example with more instructions:
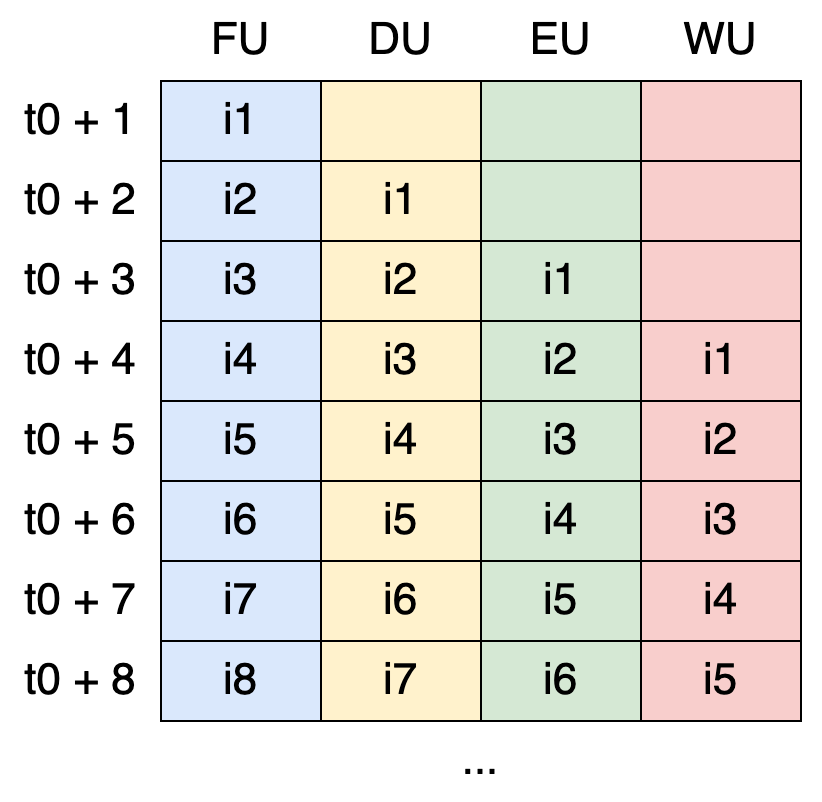
As we can see, i2, i3, i4, and i5 are completed in a single cycle each. This demonstrates the main advantage of instruction pipelining: the potential to handle one instruction per cycle, once the pipeline is full.
Now that we understand the basics of pipelining, you might be asking: why should I care as a developer? The answer lies in the importance of minimizing pipeline stalls (or bubbles). These stalls occur when one or more units are idle, waiting for something to happen before they can proceed.
Let’s delve into a concrete example to make things clear. Consider the following code:
// Something before
if(a == 0) {
foo()
} else {
bar()
}
// Something afterLet’s translate this code into pseudo-assembly:
... ; Something before
LOAD R1, a ; i1: Load a into register R1
CMP R1, #0 ; i2: Compare R1 with 0 (the result is checked in the next instruction)
BEQ ELSE ; i3: If a == 0, branch to ELSE
CALL foo ; i4: Call foo() if a == 0
JMP END ; i5: Skip ELSE section
ELSE:
CALL bar ; i6: Call bar() if a != 0
END:
; Something after
foo:
... ; Starts from i100
bar:
... ; Starts from i200The foo() function starts from i100 and the bar() function starts from i200. i3 (BEQ ELSE) is a conditional branch, meaning an instruction that causes the program to branch to a different part of the code only if a specific condition is met (here, if a == 0).
As i3 is a conditional jump, of course the FU has to wait for the result of this instruction to determine which instruction to fetch next (either i4 or i6), right?
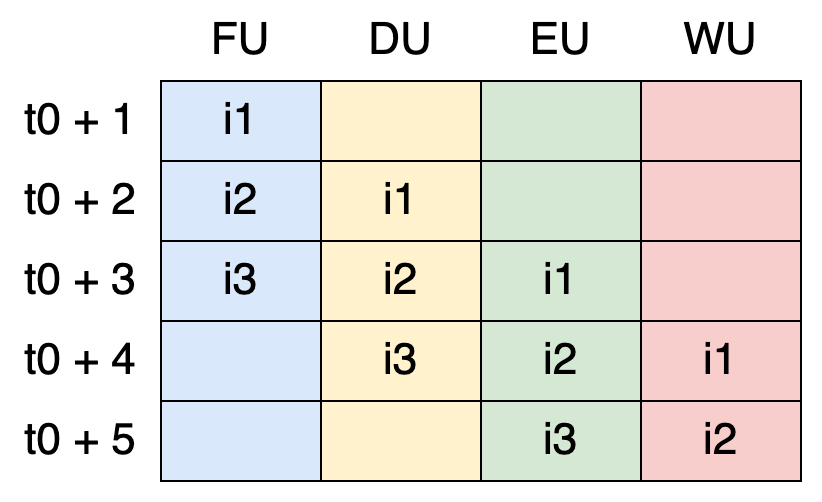
NOTE: To avoid overcomplication, we assumed that the conditional branch (
i3) is handled by the Execution Unit (EU). However, in practice, this is managed by a separate unit called the Control Unit (CU).
Theoretically, yes. Yet, the FU would be stalled for two cycles, waiting for i3 to be executed. In practice, modern CPUs use a technique called branch prediction to minimize these stalls. The idea is to predict the outcome of conditional branches before they are fully evaluated, allowing the FU to continue fetching instructions without waiting.
Discussing branch prediction techniques could probably fill a whole book and it’s far beyond my knowledge. Hence, for the scope of this post we will consider a dummy branch prediction that works this way: “assume the branch will not be taken”.
Let’s now see the effect of this prediction, assuming a == 0 (i.e., the branch is not taken):
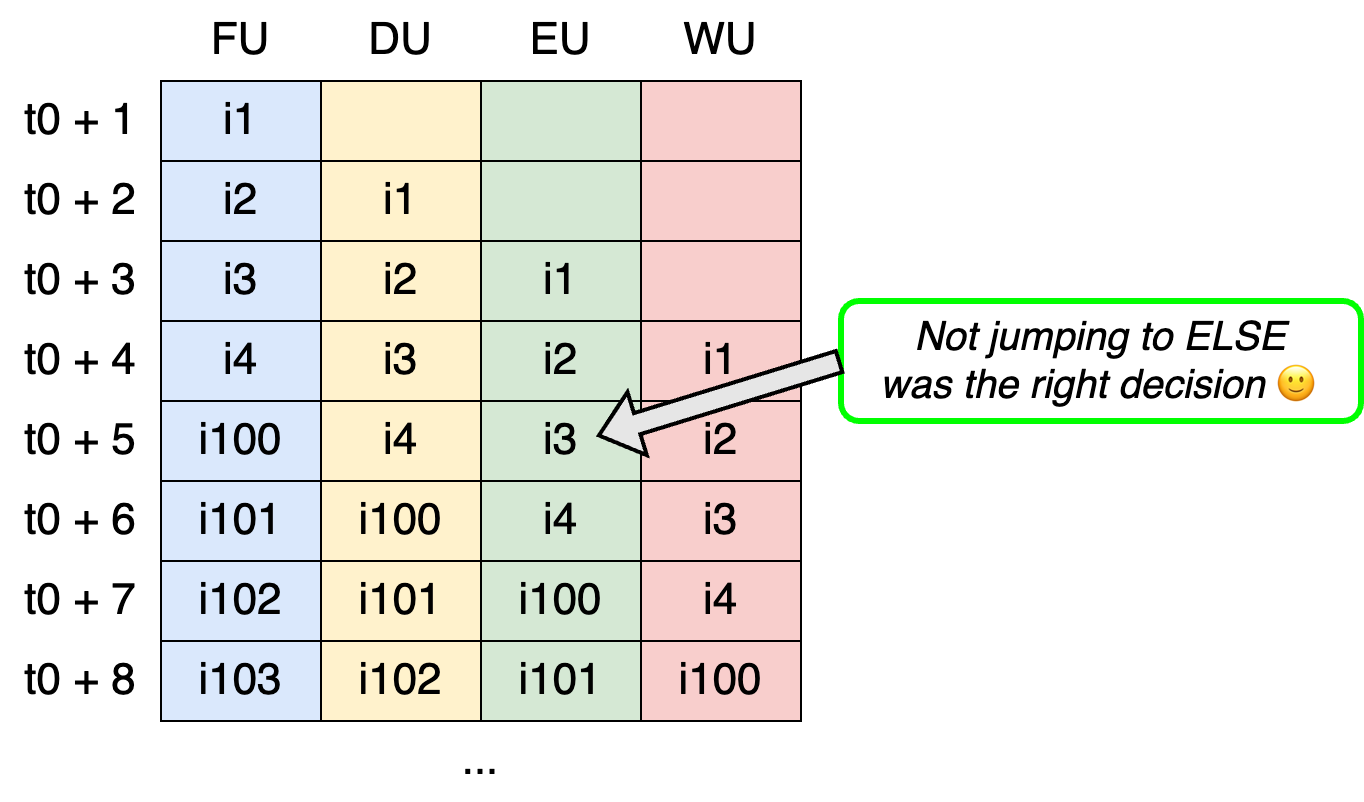
At t0 + 4, the FU doesn’t wait for i3 to complete. Instead, it automatically fetches the next predicted instruction (i4). Fortunately, i4 is the correct choice in this case, so we save two cycles.
Now, let’s consider the opposite scenario with a != 0 (i.e., the branch is taken):
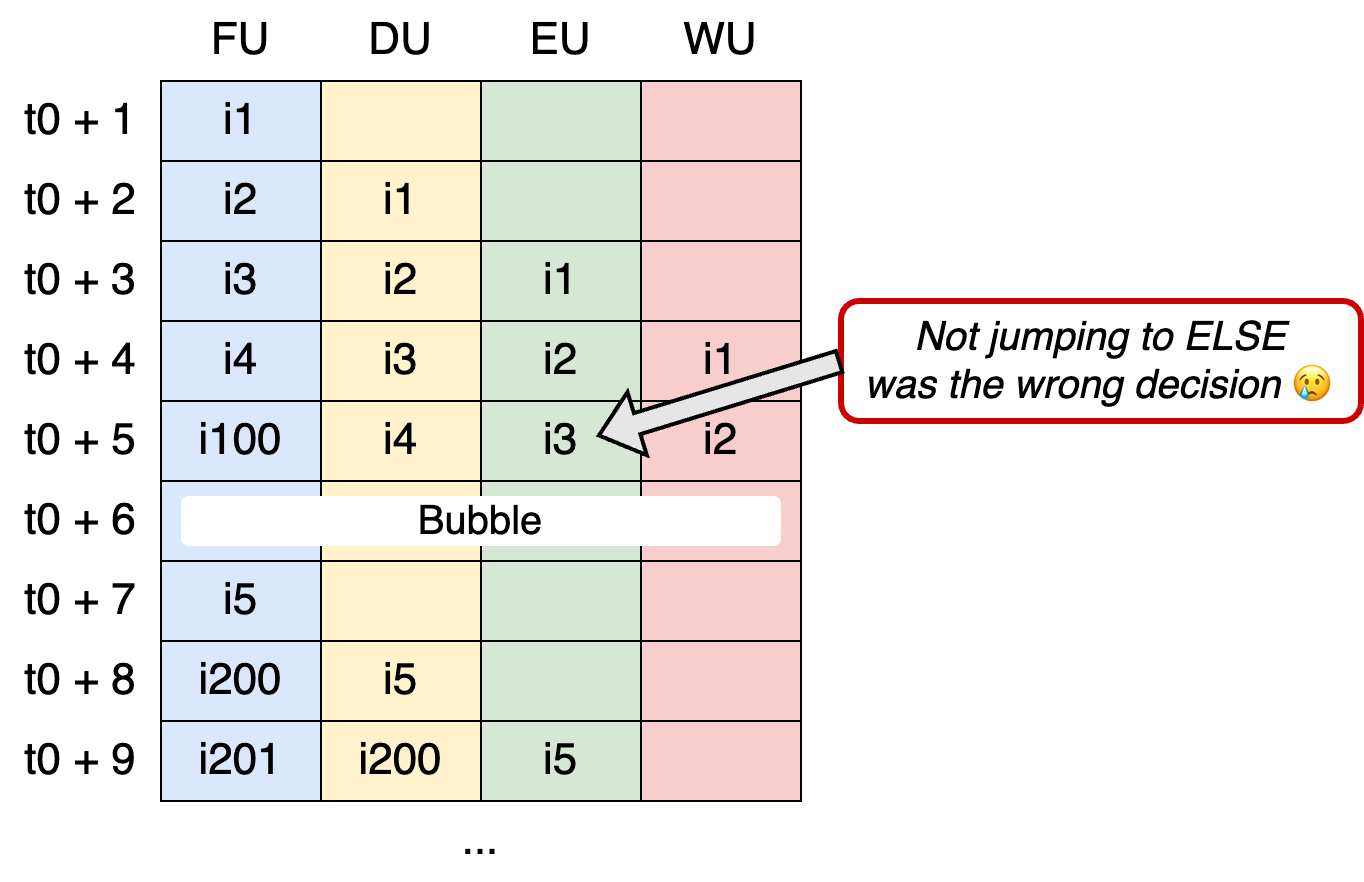
Once the EU executes i3, it realizes the prediction was wrong. This means the pipeline contains incorrect instructions (i4 and i100), which shouldn’t be executed.
In this scenario, the CPU reacts by flushing (= cleaning) the pipeline. This flushing process introduces a so-called pipeline bubble, where the pipeline is cleared of incorrect instructions, and new instructions are fetched.
In the first scenario (branch prediction was correct), i100—foo() function—is fetched at t0 + 5. Yet, in the second scenario (branch prediction is incorrect), i200—bar() function—is fetched at t0 + 8, which means we lost three cycles.
Again, this is a simplified example. In practice, the number of cycles needed to flush a pipeline depends on various factors and takes multiple cycles, leading to a noticeable impact on performance.
Back to the question of why it matters to us, developers. If we want to optimize our applications, it’s important to understand how to write code that minimizes pipeline stalls. When we do this, we can ensure that the CPU is spending less time waiting and more time processing instructions. Some techniques for reducing stalls include:
Writing branch prediction-friendly code
Minimizing data hazards (when one instruction depends on the result of a previous one)
Loop unrolling
We will discuss some of these techniques in future posts.

Explore Further
Inside the Machine: An Illustrated Introduction to Microprocessors and Computer Architecture // By far, my favorite book to understand how CPUs work. I consider this book truly fantastic.
github.com/teivah/majorana // My implementation of a virtual CPU that helped me understand these concepts more concretely. For example, implementing instruction pipelining gave me a significant performance boost.
I genuinely hope that you enjoyed this post. I strongly believe that developing some mechanical sympathy is part of the important skills to develop as a software engineer. While you may not need it straight away for every task, it will help you developing a better understanding of how software interacts, which ultimately helps in writing more efficient code.
Thermal throttling is a safety mechanism in CPUs that reduces performance to prevent overheating when the chip's temperature gets too high.